Publications
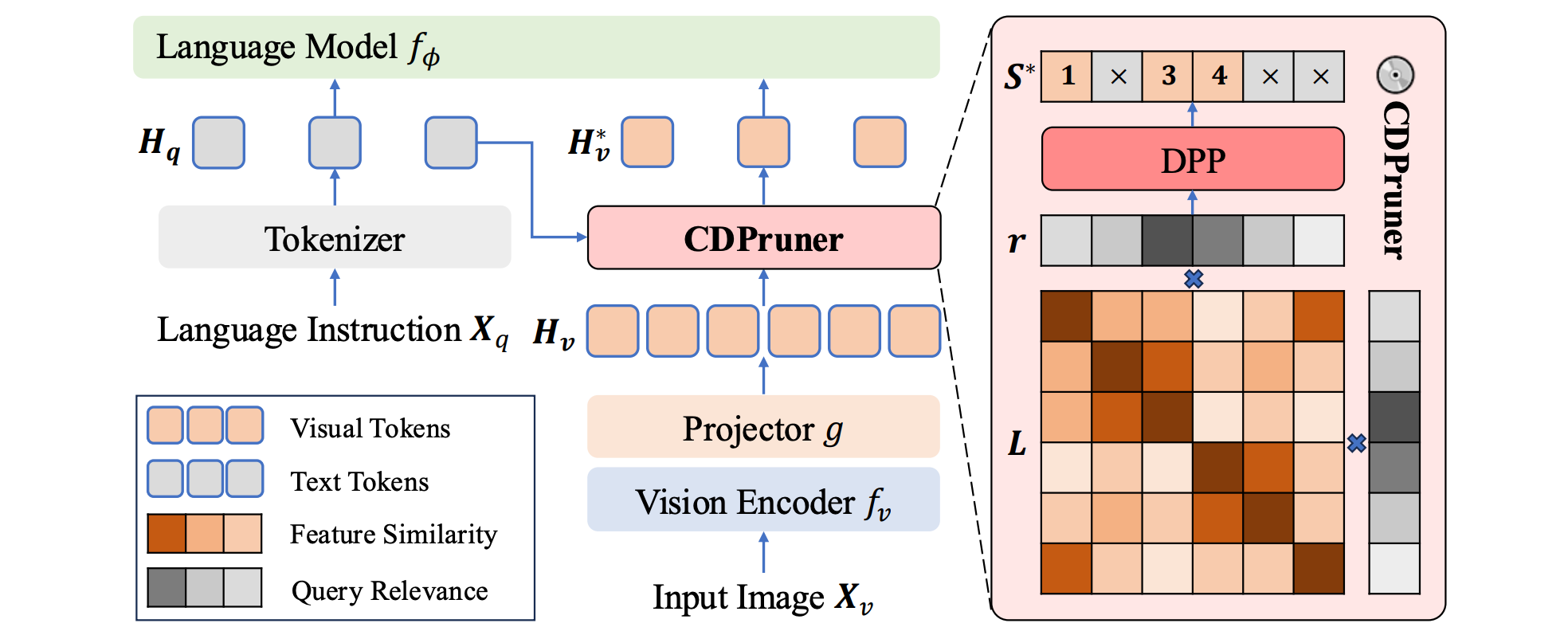
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She & Shanghang Zhang†
NeurIPS 2025 [Paper] [Code] [Website]
" We propose CDPruner as a training-free and model-agnostic visual token pruning method for MLLM inference acceleration by maximizing the conditional diversity. "
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She & Shanghang Zhang†
NeurIPS 2025 [Paper] [Code] [Website]
" We propose CDPruner as a training-free and model-agnostic visual token pruning method for MLLM inference acceleration by maximizing the conditional diversity. "
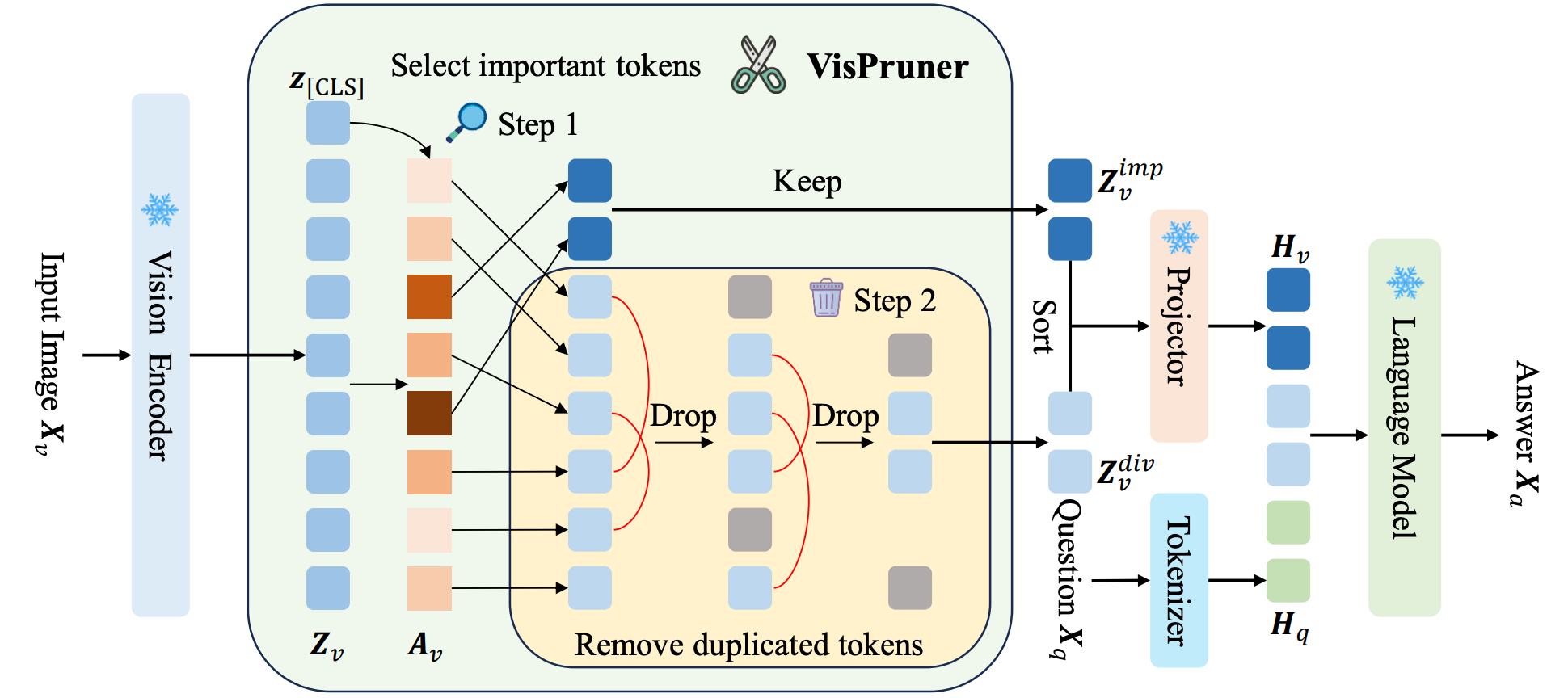
Beyond Text-Visual Attention: Exploiting Visual Cues for Effective Token Pruning in VLMs
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She & Shanghang Zhang†
ICCV 2025 [Paper] [Code] [Website]
" We propose VisPruner as a plug-and-play method that utilizes visual cues for more effective token pruning in large vision language models. "
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She & Shanghang Zhang†
ICCV 2025 [Paper] [Code] [Website]
" We propose VisPruner as a plug-and-play method that utilizes visual cues for more effective token pruning in large vision language models. "
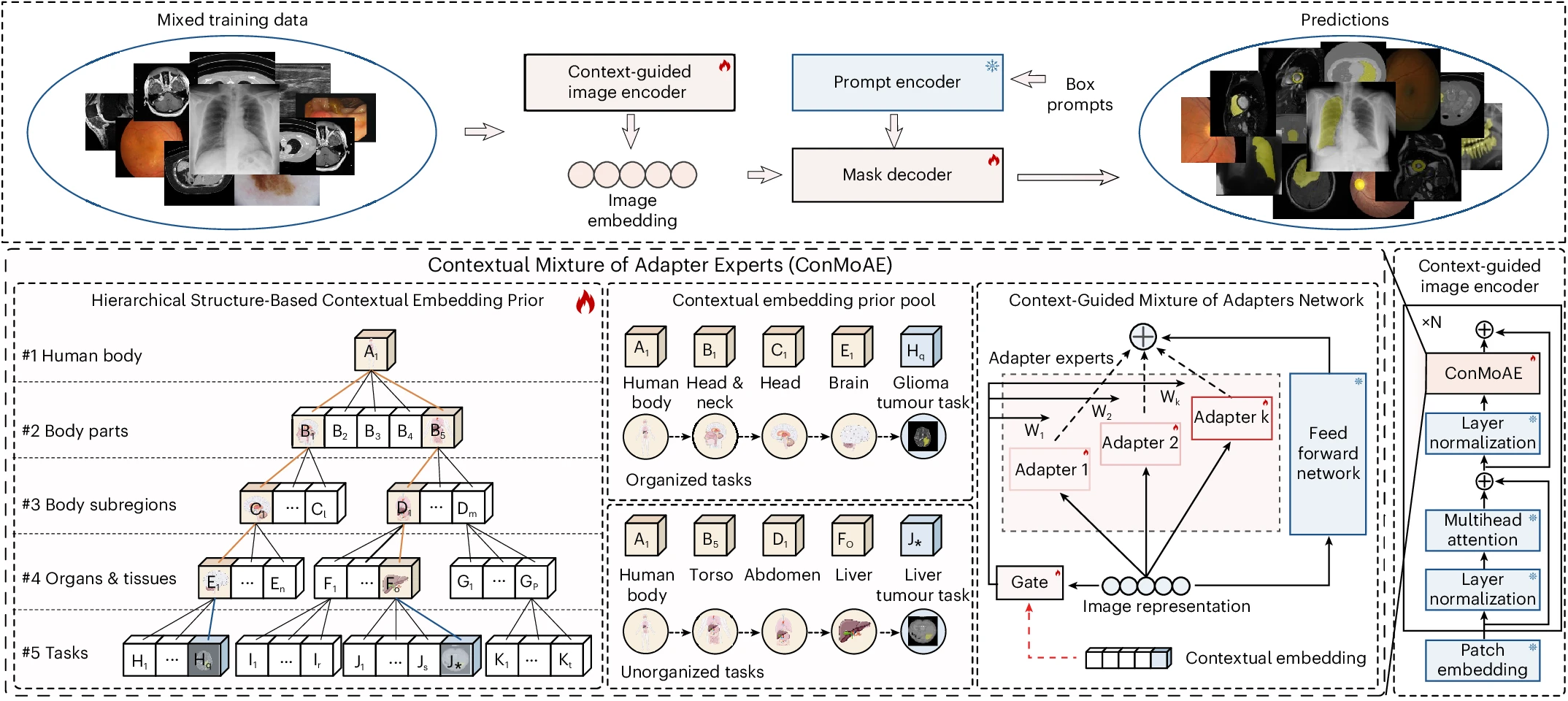
A generalist foundation model and database for open-world medical image segmentation
Siqi Zhang*, Qizhe Zhang*, Shanghang Zhang*†, Xiaohong Liu*, Jingkun Yue*, Ming Lu, Huihuan Xu, Jiaxin Yao, Xiaobao Wei, Jiajun Cao, Xiang Zhang, Ming Gao, Jun Shen, Yichang Hao, Yinkui Wang, Xingcai Zhang, Song Wu, Ping Zhang, Shuguang Cui & Guangyu Wang†
Nature Biomedical Engineering [Paper] [Code] [Model] [Data]
" We propose MedSegX as a generalist foundation model for open-world medical image segmentation, which leverages a large-scale hierarchical database MedSegDB and Contextual Mixture of Adapter Experts (ConMoAE) to achieve strong generalization across diverse modalities, organs, and clinical tasks. "
Siqi Zhang*, Qizhe Zhang*, Shanghang Zhang*†, Xiaohong Liu*, Jingkun Yue*, Ming Lu, Huihuan Xu, Jiaxin Yao, Xiaobao Wei, Jiajun Cao, Xiang Zhang, Ming Gao, Jun Shen, Yichang Hao, Yinkui Wang, Xingcai Zhang, Song Wu, Ping Zhang, Shuguang Cui & Guangyu Wang†
Nature Biomedical Engineering [Paper] [Code] [Model] [Data]
" We propose MedSegX as a generalist foundation model for open-world medical image segmentation, which leverages a large-scale hierarchical database MedSegDB and Contextual Mixture of Adapter Experts (ConMoAE) to achieve strong generalization across diverse modalities, organs, and clinical tasks. "
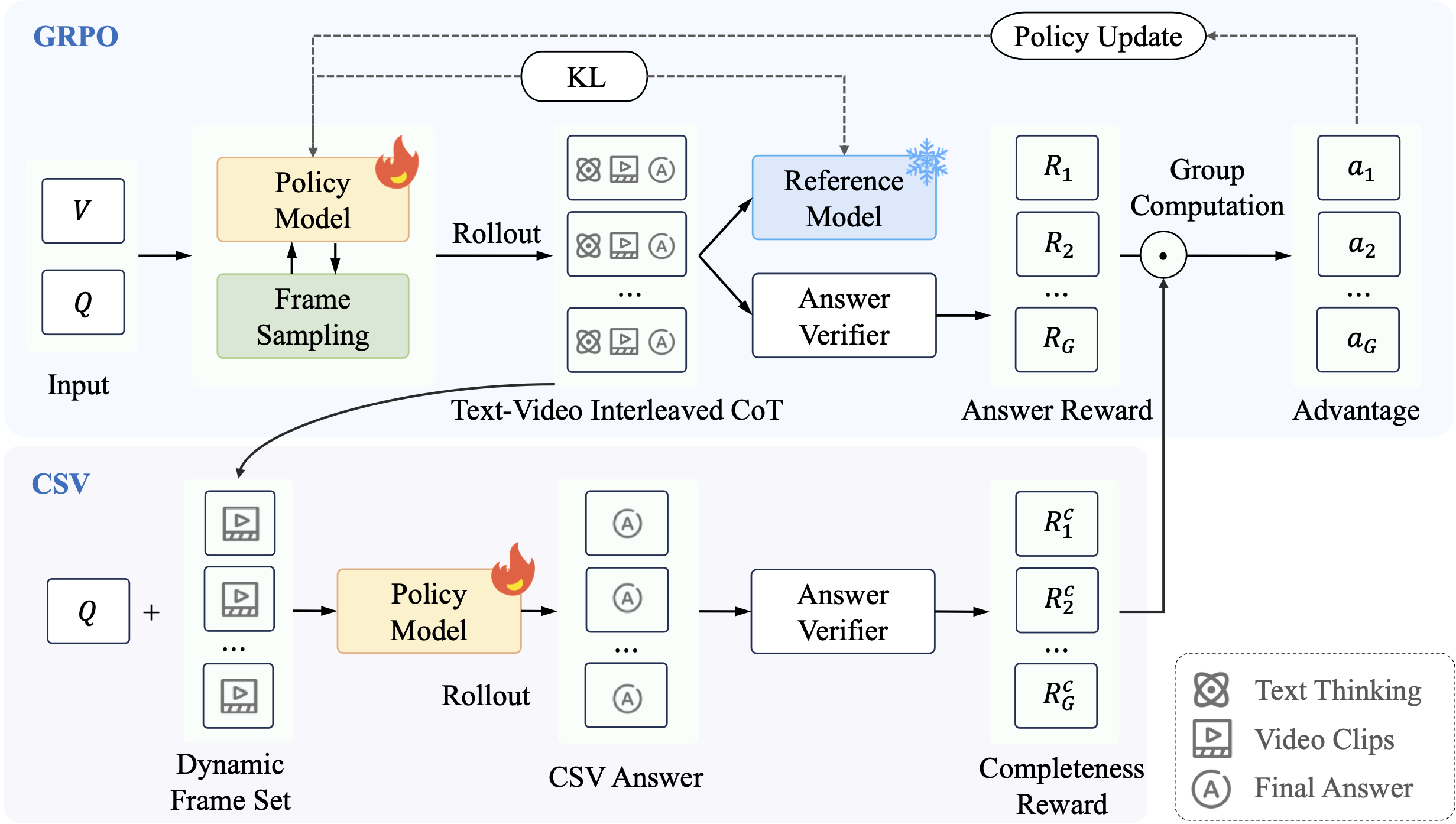
TimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Junwen Pan*, Qizhe Zhang*, Rui Zhang, Ming Lu, Xin Wan, Yuan Zhang, Chang Liu & Qi She†
ICLR 2026 [Paper] [Code] [Model]
" We propose TimeSearch-R as an end-to-end reinforcement learning framework for long-form video understanding that learns adaptive temporal search through interleaved text-video thinking and completeness self-verification. "
Junwen Pan*, Qizhe Zhang*, Rui Zhang, Ming Lu, Xin Wan, Yuan Zhang, Chang Liu & Qi She†
ICLR 2026 [Paper] [Code] [Model]
" We propose TimeSearch-R as an end-to-end reinforcement learning framework for long-form video understanding that learns adaptive temporal search through interleaved text-video thinking and completeness self-verification. "

Gradient-based Parameter Selection for Efficient Fine-Tuning
Zhi Zhang*, Qizhe Zhang*, Zijun Gao, Renrui Zhang, Ekaterina Shutova, Shiji Zhou & Shanghang Zhang†
CVPR 2024 [Paper] [Code]
" We propose a novel gradient-based parameter selection (GPS) method for effeicient fine-tuning. GPS does not introduce any additional storage or computational cost during both training and inference stages. Moreover, it possesses model-agnostic and task-adaptive properties, achieving outstanding performance. "
Zhi Zhang*, Qizhe Zhang*, Zijun Gao, Renrui Zhang, Ekaterina Shutova, Shiji Zhou & Shanghang Zhang†
CVPR 2024 [Paper] [Code]
" We propose a novel gradient-based parameter selection (GPS) method for effeicient fine-tuning. GPS does not introduce any additional storage or computational cost during both training and inference stages. Moreover, it possesses model-agnostic and task-adaptive properties, achieving outstanding performance. "

Unsupervised Spike Depth Estimation via Cross-modality Cross-domain Knowledge Transfer
Jiaming Liu*, Qizhe Zhang*, Xiaoqi Li, Jianing Li, Guanqun Wang†, Ming Lu, Tiejun Huang & Shanghang Zhang†
ICRA 2024 [Paper] [Code]
" We propose a novel cross-modality cross-domain (BiCross) framework for unsupervised spike depth estimation. To be mentioned, we are the first to exploit the opensource RGB datasets to help unsupervised learning for spike depth estimation. "
Jiaming Liu*, Qizhe Zhang*, Xiaoqi Li, Jianing Li, Guanqun Wang†, Ming Lu, Tiejun Huang & Shanghang Zhang†
ICRA 2024 [Paper] [Code]
" We propose a novel cross-modality cross-domain (BiCross) framework for unsupervised spike depth estimation. To be mentioned, we are the first to exploit the opensource RGB datasets to help unsupervised learning for spike depth estimation. "
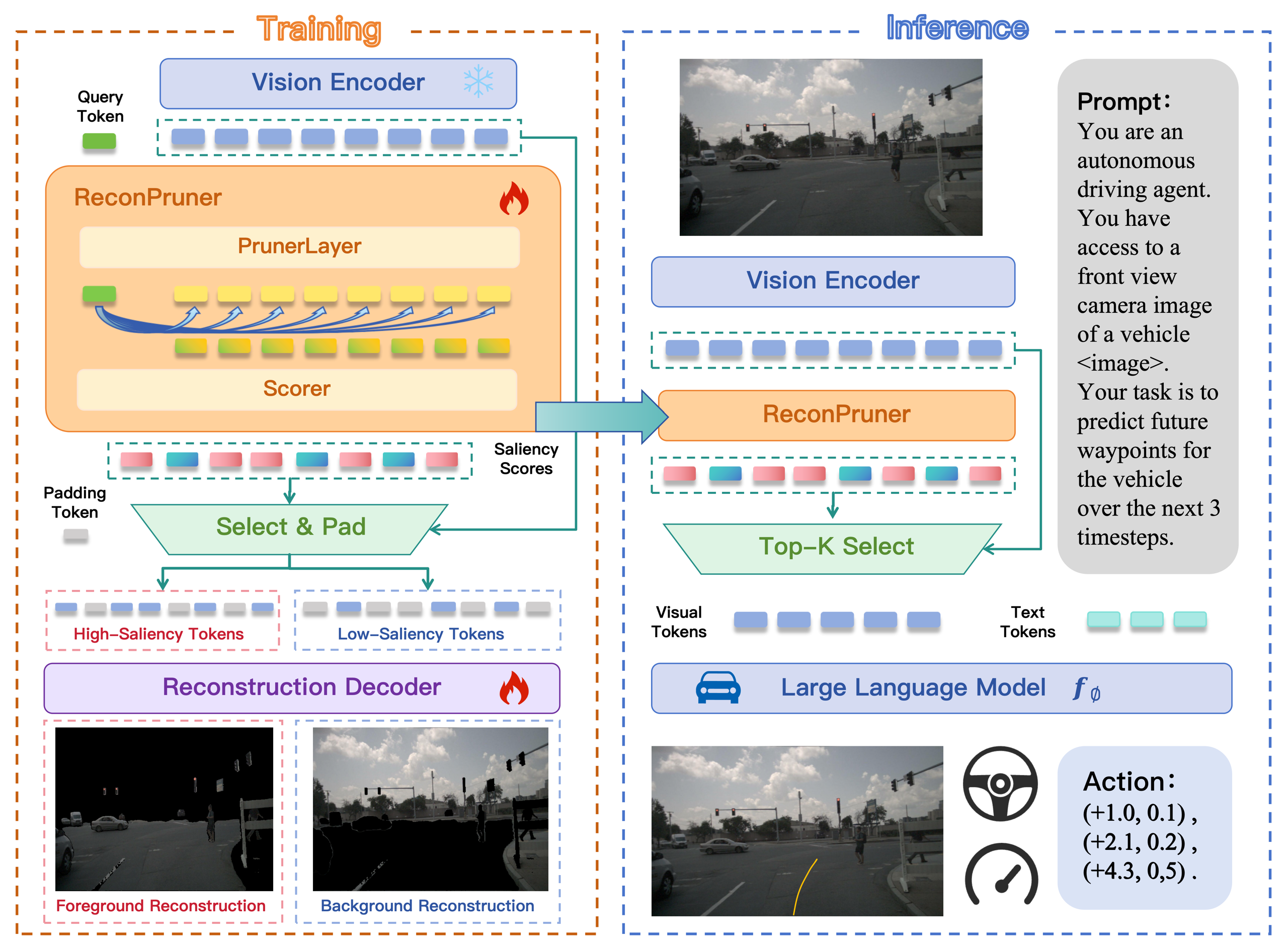
FastDriveVLA: Efficient End-to-End Driving via Plug-and-Play Reconstruction-based Token Pruning
Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Xiaobao Wei, Sixiang Chen, Liyun Li, Xianming Liu, Ming Lu, Yang Wang† & Shanghang Zhang†
AAAI 2026 [Paper]
" We propose FastDriveVLA as a plug-and-play reconstruction-based visual token pruning framework for efficient end-to-end autonomous driving by preserving foreground information critical to driving decisions. "
Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Xiaobao Wei, Sixiang Chen, Liyun Li, Xianming Liu, Ming Lu, Yang Wang† & Shanghang Zhang†
AAAI 2026 [Paper]
" We propose FastDriveVLA as a plug-and-play reconstruction-based visual token pruning framework for efficient end-to-end autonomous driving by preserving foreground information critical to driving decisions. "
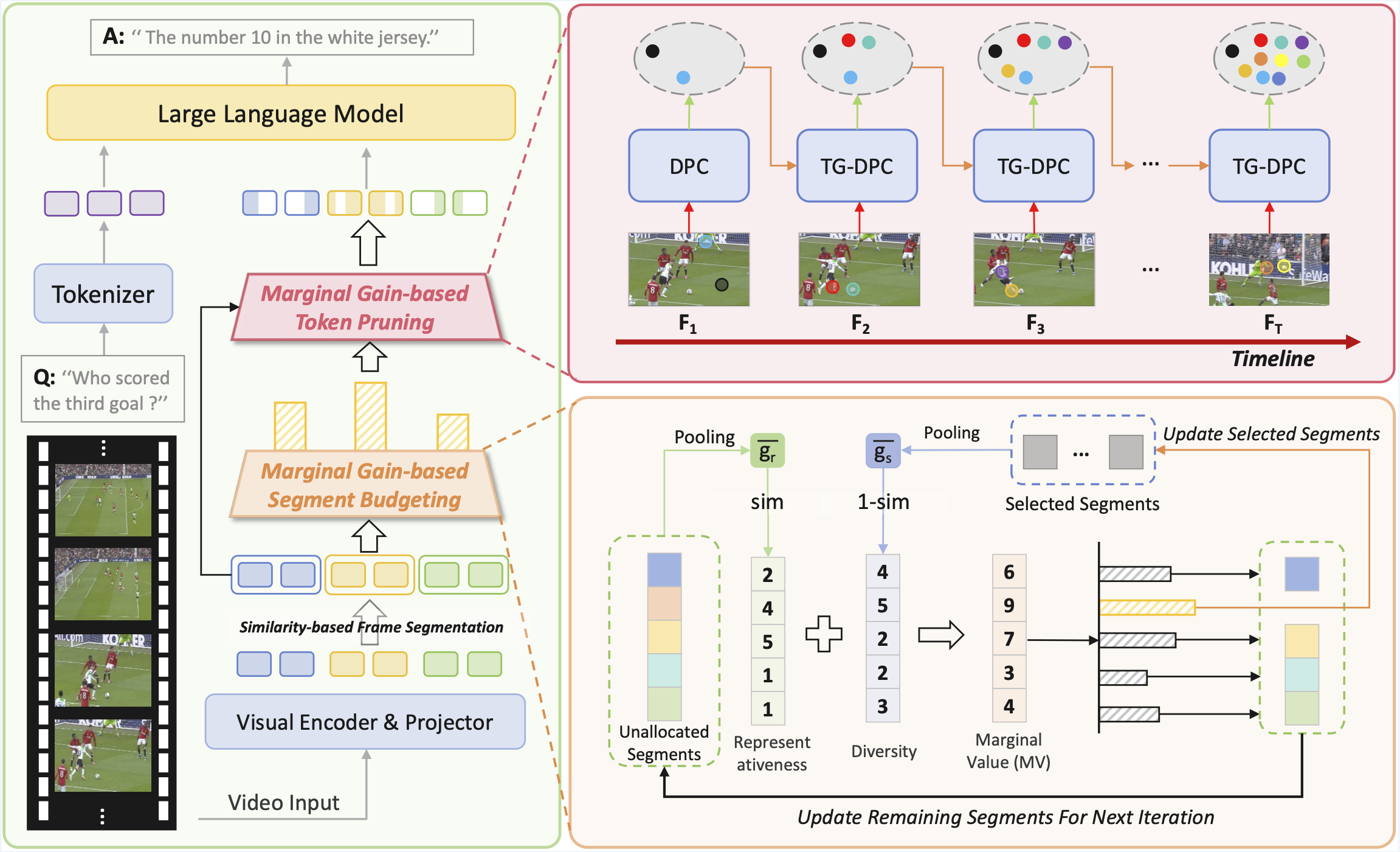
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
Junpeng Ma, Qizhe Zhang, Ming Lu, Zhibin Wang, Qiang Zhou, Jun Song & Shanghang Zhang†
AAAI 2026 [Paper]
" We propose MMG-Vid as a training-free video token pruning framework for efficient Video LLM inference by maximizing marginal gains at both segment and token levels. "
Junpeng Ma, Qizhe Zhang, Ming Lu, Zhibin Wang, Qiang Zhou, Jun Song & Shanghang Zhang†
AAAI 2026 [Paper]
" We propose MMG-Vid as a training-free video token pruning framework for efficient Video LLM inference by maximizing marginal gains at both segment and token levels. "
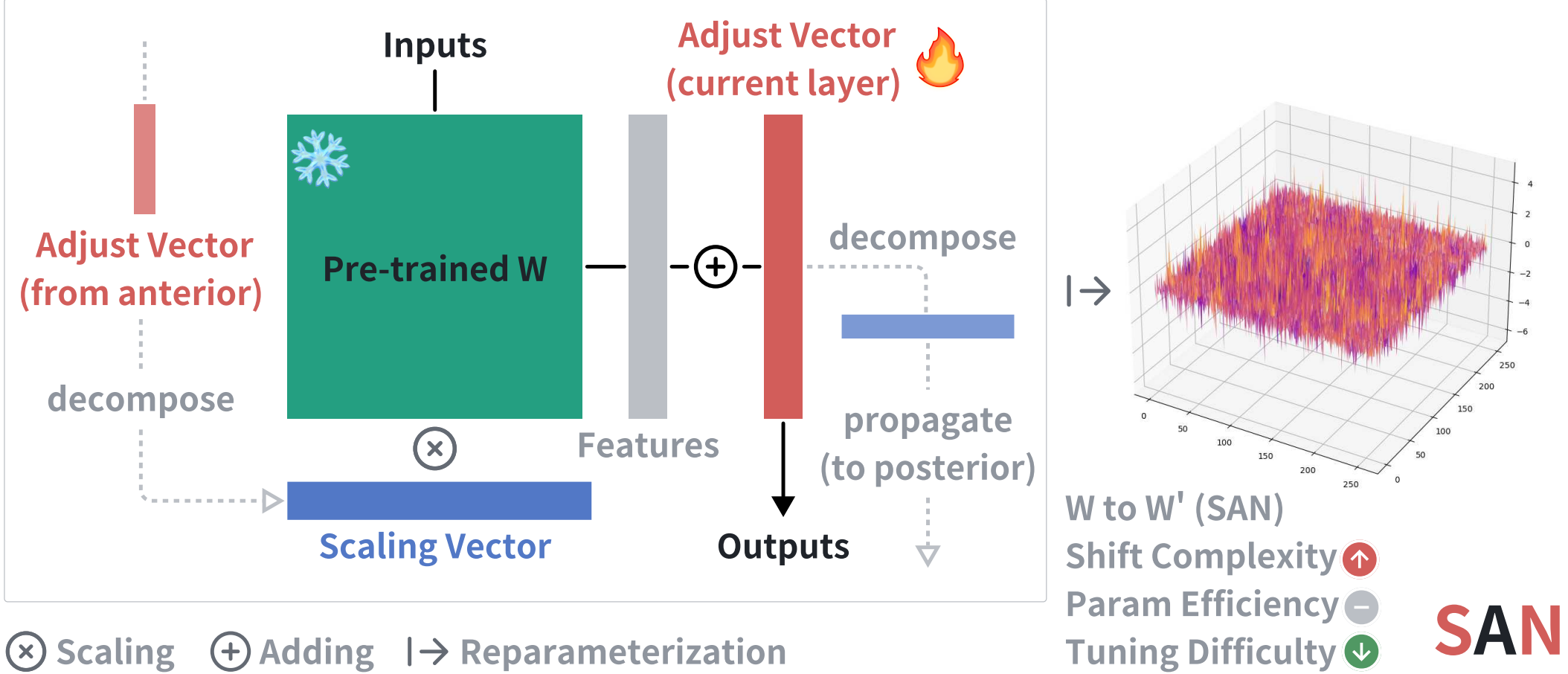
SAN: Hypothesizing Long-Term Synaptic Development and Neural Engram Mechanism in Scalable Model's Parameter-Efficient Fine-Tuning
Gaole Dai, Yiming Tang, Chunkai Fan, Qizhe Zhang, Zhi Zhang, Yulu Gan, Chengching Tseng, Shanghang Zhang† & Tiejun Huang†
ICML 2025 [Paper] [Code]
" We propose Synapse and Neuron (SAN), which decomposes and propagates scaling components from anterior feature adjusting vectors towards posterior weight matrices. SAN is theoretically grounded in Long-Term Potentiation/Depression phenomena, which govern synapse development through neurotransmitter release modulation. "
Gaole Dai, Yiming Tang, Chunkai Fan, Qizhe Zhang, Zhi Zhang, Yulu Gan, Chengching Tseng, Shanghang Zhang† & Tiejun Huang†
ICML 2025 [Paper] [Code]
" We propose Synapse and Neuron (SAN), which decomposes and propagates scaling components from anterior feature adjusting vectors towards posterior weight matrices. SAN is theoretically grounded in Long-Term Potentiation/Depression phenomena, which govern synapse development through neurotransmitter release modulation. "

MoVE-KD: Knowledge Distillation for VLMs with Mixture of Visual Encoders
Jiajun Cao, Yuan Zhang, Tao Huang, Ming Lu, Qizhe Zhang, Ruichuan An, Ningning Ma & Shanghang Zhang†
CVPR 2025 [Paper] [Code]
" We propose Mixture-of-Visual-Encoder Knowledge Distillation (MoVE-KD), a novel framework that distills the unique proficiencies of multiple vision encoders into a single, efficient encoder model. "
Jiajun Cao, Yuan Zhang, Tao Huang, Ming Lu, Qizhe Zhang, Ruichuan An, Ningning Ma & Shanghang Zhang†
CVPR 2025 [Paper] [Code]
" We propose Mixture-of-Visual-Encoder Knowledge Distillation (MoVE-KD), a novel framework that distills the unique proficiencies of multiple vision encoders into a single, efficient encoder model. "

Adaptive Distribution Masked Autoencoders for Continual Test-Time Adaptation
Jiaming Liu*, Ran Xu*, Senqiao Yang*, Renrui Zhang, Qizhe Zhang, Zehui Chen, Yandong Guo & Shanghang Zhang†
CVPR 2024 [Paper] [Code] [Website]
" We propose Adaptive Distribution Masked Autoencoders (ADMA) as a novel continual self-supervised method. ADMA enhances the extraction of target domain knowledge while mitigating the accumulation of distribution shifts. "
Jiaming Liu*, Ran Xu*, Senqiao Yang*, Renrui Zhang, Qizhe Zhang, Zehui Chen, Yandong Guo & Shanghang Zhang†
CVPR 2024 [Paper] [Code] [Website]
" We propose Adaptive Distribution Masked Autoencoders (ADMA) as a novel continual self-supervised method. ADMA enhances the extraction of target domain knowledge while mitigating the accumulation of distribution shifts. "

Exploring Sparse Visual Prompt for Cross-domain Semantic Segmentation
Senqiao Yang*, Jiarui Wu*, Jiaming Liu*, Xiaoqi Li, Qizhe Zhang, Mingjie Pan & Shanghang Zhang†
AAAI 2024 [Paper] [Code] [Website]
" We propose a novel Sparse Visual Domain Prompts (SVDP) approach for dense prediction TTA tasks, which holds minimal trainable parameters in the image-level prompt and reserves more spatial information of the input. "
Senqiao Yang*, Jiarui Wu*, Jiaming Liu*, Xiaoqi Li, Qizhe Zhang, Mingjie Pan & Shanghang Zhang†
AAAI 2024 [Paper] [Code] [Website]
" We propose a novel Sparse Visual Domain Prompts (SVDP) approach for dense prediction TTA tasks, which holds minimal trainable parameters in the image-level prompt and reserves more spatial information of the input. "